
Der Unterschied: Klassische Software vs. KI
Klassisch: Input + Regeln = Output (Starr) KI: Input + Output (Beispiele) = Regeln (Flexibel gelernt)
Einführung in die Künstliche Intelligenz
Künstliche Intelligenz (KI) ist ein weitreichendes Konzept, das verschiedene Technologien und Ansätze umfasst, die Maschinen in die Lage versetzen, menschenähnliche Entscheidungsfindung und Lernfähigkeiten zu zeigen. Der Begriff bezieht sich auf Systeme oder Programme, die Aufgaben ausführen, die normalerweise menschliche Intelligenz erfordern, wie z. B. Sprachverarbeitung, Bilderkennung, Problemlösung und adaptives Lernen. KI hat in den letzten Jahren erheblich an Bedeutung gewonnen und prägt zunehmend viele Bereiche unseres Lebens.
Das Interesse an Künstlicher Intelligenz wird durch ihre vielschichtigen Anwendungen in verschiedenen Sektoren gesteigert. In der Wirtschaft ermöglicht KI die Automatisierung wiederkehrender Aufgaben, wodurch Effizienz und Produktivität steigen. In der Medizin hilft sie bei der Diagnose von Krankheiten und der Entwicklung individueller Therapiepläne. Im Bildungsbereich unterstützt KI Lernplattformen, die auf die Bedürfnisse einzelner Schüler zugeschnitten sind. Diese Beispiele verdeutlichen, wie KI-Technologien unser tägliches Leben beeinflussen.
Ein grundlegendes Ziel der Künstlichen Intelligenz ist es, Systeme zu schaffen, die selbstständig lernen und handeln können. Dies geschieht durch den Einsatz von Algorithmen und großen Datensätzen, die verarbeiten werden, um Muster zu erkennen und Vorhersagen zu treffen. Maschinelles Lernen, ein Teilbereich der KI, hat sich als besonders wirksam erwiesen, da es Maschinen ermöglicht, aus Erfahrungen zu lernen und ihre Leistung kontinuierlich zu verbessern. Eine weitere spannende Entwicklung in der KI ist die Verwendung von neuronalen Netzwerken, die die Funktionsweise des menschlichen Gehirns nachahmen und komplexe Probleme effizient lösen können.
Die Grundprinzipien der Künstlichen Intelligenz
Die grundlegenden Prinzipien der Künstlichen Intelligenz (KI) basieren auf dem Bestreben, menschliche kognitive Prozesse nachzuahmen und Problemlösungen mithilfe von Computern effizient zu gestalten. Künstliche Intelligenz zielt darauf ab, Systeme zu entwickeln, die in der Lage sind, zu lernen, zu schlussfolgern und Entscheidungen zu treffen, ähnlich wie es ein Mensch tut. Ein zentrales Ziel der KI ist es, Daten zu analysieren und daraus Muster zu erkennen, um Vorhersagen oder Empfehlungen zu geben.
Ein Hauptprinzip der KI ist das maschinelle Lernen, das es Computern ermöglicht, aus Erfahrungen zu lernen und ihre Leistung im Laufe der Zeit zu verbessern, ohne explizit programmiert zu werden. In diesem Kontext werden Algorithmen eingesetzt, um große Datenmengen zu verarbeiten, die als Trainingsdaten für KI-Modelle dienen. Die Herausforderung besteht darin, diese Modelle so zu gestalten, dass sie nicht nur genaue Ergebnisse liefern, sondern auch in der Lage sind, aus neuartigen Situationen zu lernen.
Grundpfeiler der modernen KI
Einführung in die drei Ebenen der Technik-Algorithmen:
Moderne KI-Technologien basieren auf drei fundamentalen Ebenen: mathematische Formeln, Rechenpower und die Verfügbarkeit von Big Data. Diese Komponenten sind entscheidend, um Algorithmen zu entwickeln, die aus Daten lernen können.
Mathematische Formeln
Mathematische Formeln sind der Kern von Algorithmen. Ein Beispiel ist der Backpropagation-Algorithmus, welcher das Lernen von KI-Modellen ermöglicht. Durch die Anpassung der Gewichtungen in neuronalen Netzen können diese komplexe Muster in den Daten erkennen und von ihnen lernen.
Rechenpower und Big Data
Die Rechenleistung ist ebenfalls ein entscheidender Faktor. Moderne KI benötigt spezialisierte Grafikchips, oftmals GPUs von Herstellern wie NVIDIA, um Milliarden von Berechnungen simultan durchzuführen. Ohne diese immense Rechenpower bleiben KI-Modelle oft ineffizient und unbrauchbar.
Zusätzlich dazu ist das Vorhandensein großer Datenmengen, also Big Data, unerlässlich. Ohne umfangreiche Text- und Bilddaten oder umfassende Codes wie ABAP hat eine KI keinen Kontext oder Informationen, um zu lernen und sich weiterzuentwickeln. Diese drei Ebenen – mathematische Formeln, Rechenpower und Daten – arbeiten also Hand in Hand, um die heutigen KI-Systeme zu stärken.
Ein weiterer Aspekt der Künstlichen Intelligenz ist die Verarbeitung natürlicher Sprache, bei der KI-Systeme verwendet werden, um menschliche Sprache zu verstehen und zu generieren. Dies erfordert komplexe Algorithmen, die Syntax, Semantik und Kontext berücksichtigen müssen, was die Entwicklung effektiver Kommunikationsschnittstellen zwischen Mensch und Maschine erschwert. Zudem steht die Fähigkeit der KI, Emotionen und Intentionen zu interpretieren, im Mittelpunkt der Forschung, da dies entscheidend für die Interaktion zwischen Mensch und KI ist.
Dabei müssen Entwickler stets im Hinterkopf behalten, dass die Nachbildung von menschlichem Lernen und Problemlösungsprozessen nie vollständig erreicht werden kann, da menschliche Intuition und Erfahrung ebenso wesentliche Elemente sind. Obwohl große Fortschritte erzielt wurden, bleibt die Schaffung eines vollkommen autonomen KI-Systems eine große Herausforderung.
Maschinelles Lernen: Das Herz der Künstlichen Intelligenz
Maschinelles Lernen stellt einen bedeutenden Bestandteil der Künstlichen Intelligenz (KI) dar. Es bezieht sich auf die Fähigkeit von Maschinen, aus Erfahrungen zu lernen und Muster in Daten zu erkennen, ohne explizit dafür programmiert zu werden. Diese Lernmethoden sind nicht nur auf programmierte Regeln angewiesen, sondern sie verbessern sich kontinuierlich durch die Verarbeitung von großen Datenmengen.
Die Grundlage des maschinellen Lernens bildet die Verwendung von Algorithmen, die dazu dienen, Daten zu analysieren, Vorhersagen zu treffen oder Entscheidungen zu unterstützen. Diese Algorithmen verarbeiten verschiedene Arten von Informationen, um auf Basis der erlernten Muster Ergebnisse zu erzielen. Dabei kann maschinelles Lernen in drei Hauptkategorien unterteilt werden: überwacht, unüberwacht und bestärkend. Bei überwachten Lernansätzen wird das Modell mit beschrifteten Daten trainiert, während unüberwachtes Lernen mit unbeaufsichtigten Daten funktioniert, um Strukturen und Muster zu erkennen. Der bestärkende Ansatz hingegen belohnt das Modell bei erfolgreichen Entscheidungen und verbessert somit dessen Leistung über Zeit.
Die Relevanz von maschinellem Lernen erstreckt sich über zahlreiche Anwendungsbereiche, von der Bild- und Spracherkennung bis hin zur prädiktiven Analyse und im Gesundheitswesen. Firmen verwenden zunehmend maschinelles Lernen, um ihre Geschäftsstrategien zu optimieren und ein tieferes Verständnis für Markttrends und Kundenverhalten zu gewinnen. Der Einsatz dieser Technologie verbessert nicht nur die Effizienz, sondern fördert auch Innovationen. Der Fortschritt in den Bereichen Rechenleistung und Datenverfügbarkeit hat dazu geführt, dass das maschinelle Lernen eine Schlüsselrolle in der Entwicklung von modernen KI-Anwendungen spielt.
Die Rolle des Deep Learning in der KI
Deep Learning stellt einen bedeutenden Teilbereich innerhalb der Künstlichen Intelligenz (KI) dar, der durch den Einsatz von neuronalen Netzwerken charakterisiert ist. Im Gegensatz zum maschinellen Lernen, welches auf statistischen Methoden basiert, nutzt Deep Learning komplexe Architekturen, um aus großen Datenmengen zu lernen. Diese Methode ist besonders effektiv bei der Verarbeitung von unstrukturierten Daten, wie etwa Bildern, Texten und Audiosignalen.
Der Hauptunterschied zwischen dem maschinellen Lernen und Deep Learning liegt in der Tiefe des Modells. Während maschinelles Lernen oft flächendeckende Algorithmen verwendet, bei denen Merkmale manuell extrahiert werden, setzt Deep Learning auf mehrere Schichten von Neuronen, die in der Lage sind, automatisch nützliche Merkmale aus den Eingabedaten zu lernen. Diese vielschichtige Architektur ermöglicht es Deep Learning-Modellen, tiefere und abstraktere Muster zu erfassen, was insbesondere in Bereichen wie der Bild- und Sprachverarbeitung von Vorteil ist.
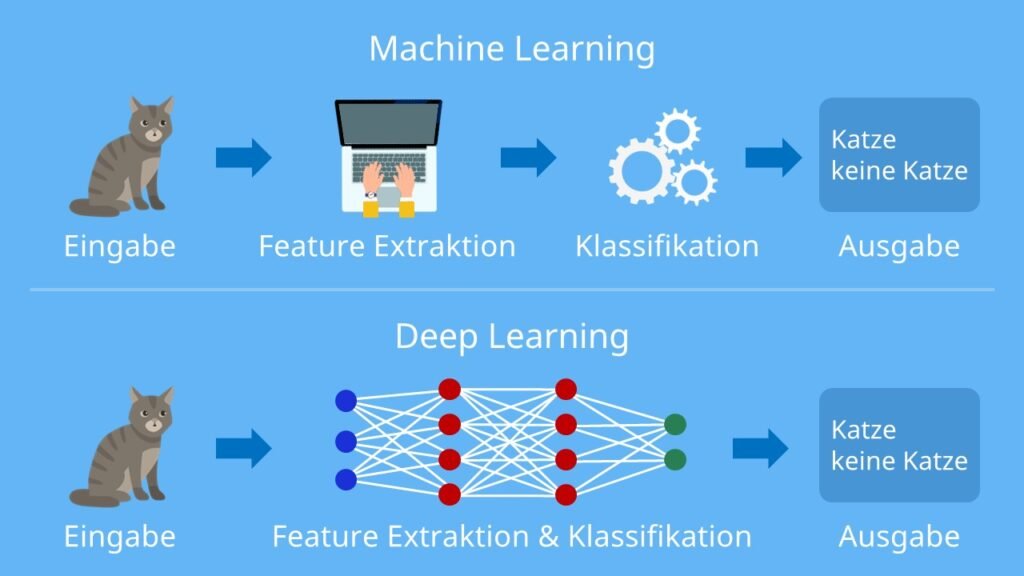
Ein weiterer Vorteil von Deep Learning besteht darin, dass es große Mengen an Daten effizient verarbeiten kann, wodurch es zunehmend beliebter wird, insbesondere im Zeitalter von Big Data. Fortschritte in der Rechenleistung, insbesondere durch GPUs, haben dazu beigetragen, dass Deep Learning für zahlreiche Anwendungen in der KI an Bedeutung gewonnen hat. Die Fähigkeit, vielfältige und komplexe Aufgaben zu bewältigen, macht Deep Learning zu einem Schlüsselkonzept in der modernen Künstlichen Intelligenz.
Neuronale Netze: Die Struktur hinter der Intelligenz
Neuronale Netze sind ein zentraler Bestandteil der Künstlichen Intelligenz (KI) und basieren auf Konzepten, die dem menschlichen Gehirn nachempfunden sind. Diese Technologien bestehen aus einer Anordnung von interagierenden Knoten oder „Neuronen“, die Informationen verarbeiten und Aufgaben erfüllen. Die Struktur neuronaler Netze ist in verschiedene Schichten unterteilt: Eingabeschicht, versteckte Schichten und Ausgabeschicht. Jede Schicht hat spezifische Funktionen, die zusammenarbeiten, um komplexe Aufgaben zu bewältigen.
Die Eingabeschicht erhält die Daten, die analysiert werden sollen, und überträgt diese an die versteckten Schichten. In den versteckten Schichten wird die Information durch verschiedene Rechenoperationen transformiert. Jedes Neuron innerhalb dieser Schichten hat eine Gewichtung, die angepasst wird, um die Netzwerkleistung zu optimieren. Diese Gewichtungen verändern sich während des Trainingsprozesses, der oft durch einen sogenannten Rückpropagierungsalgorithmus unterstützt wird. Dieser Ansatz ermöglicht es dem Netzwerk, aus Fehlern zu lernen und seine Vorhersagen zu verbessern.
Die Ausgabeschicht liefert schließlich das Endergebnis der Berechnungen. In vielen Anwendungen von neuronalen Netzen wird versucht, Muster zu erkennen, Klassifikationen durchzuführen oder sogar Text und Sprache zu generieren. Diese Technologien finden Anwendung in vielfältigen Bereichen, darunter Bild- und Spracherkennung, medizinische Diagnosen und Finanzanalysen. Das Verständnis der Struktur und Funktionsweise von neuronalen Netzen ist somit entscheidend für die Weiterentwicklung von Künstlicher Intelligenz und deren Anwendungen in der realen Welt.
Mustererkennung und ihre Bedeutung für die KI
Mustererkennung ist ein zentraler Bestandteil der Künstlichen Intelligenz (KI). Sie bezieht sich auf die Fähigkeit von Maschinen, aus Daten Muster zu erkennen, zu analysieren und darauf basierend Entscheidungen zu treffen. Durch den Einsatz fortgeschrittener Algorithmen kann KI eine Vielzahl von Mustern identifizieren, die für Menschen oft nicht offensichtlich sind. Diese Fähigkeit ist besonders nützlich in Bereichen wie der Bild- und Sprachverarbeitung, wo große Datenmengen effizient verarbeitet werden müssen.
Ein Beispiel für Mustererkennung in der KI ist die Identifizierung von Gesichtern in Fotos. Algorithmen können Merkmale wie Augen, Nase und Mund erkennen und die Daten mit bestehenden Mustern abgleichen. Diese Anwendungen sind nicht nur in sozialen Netzwerken, sondern auch in Sicherheitsdiensten von Bedeutung, da sie einen wichtigen Beitrag zur Identifikation von Personen leisten können.
Darüber hinaus spielt Mustererkennung eine wesentliche Rolle in der Analyse von Datenströmen. In der Finanzwelt beispielsweise können KI-Modelle historische Daten analysieren, um Trends und Muster zu erkennen, die zur Vorhersage zukünftiger Marktbewegungen genutzt werden können. Diese Vorhersagen helfen Anlegern, fundierte Entscheidungen zu treffen und potenzielle Risiken besser zu bewerten.
Ebenfalls relevant ist die Mustererkennung in der Medizin, wo KI-gestützte Systeme in der Lage sind, Krankheitsmuster in bildgebenden Verfahren zu identifizieren. Solche Technologien verbessern die Diagnostik und ermöglichen eine frühzeitige Erkennung von Krankheiten, was zu besseren Behandlungsmöglichkeiten führt. Zusammenfassend lässt sich feststellen, dass die Mustererkennung eine Schlüsseltechnologie innerhalb der KI ist, die innovative Lösungen in vielen Branchen ermöglicht.
Anwendungen der Künstlichen Intelligenz im Alltag
Künstliche Intelligenz (KI) hat sich in zahlreichen Bereichen unseres täglichen Lebens etabliert und revolutioniert die Art und Weise, wie wir mit Technologie interagieren. In der Automatisierung beispielsweise ermöglicht KI die Effizienzsteigerung in der Industrie. Roboter und Maschinen, die mit KI-Technologien ausgestattet sind, können repetitive Aufgaben schneller und präziser durchführen als Menschen. Dies reduziert nicht nur die Produktionskosten, sondern steigert auch die Qualität der Endprodukte.
Ein weiteres bemerkenswertes Anwendungsgebiet der KI findet sich in der Medizin. Hier kommen KI-Systeme zum Einsatz, um Diagnosen zu stellen und personalisierte Behandlungspläne zu entwickeln. Beispielsweise können Algorithmen Muster in riesigen medizinischen Datensätzen erkennen, die menschlichen Ärzten möglicherweise entgehen. Dadurch wird nicht nur die Genauigkeit der Diagnosen verbessert, sondern auch die Geschwindigkeit, mit der Krankheitsbilder erkannt werden. Anwendungen wie bildgebende Verfahren und Robotergestützte Chirurgie sind weitere Beispiele dafür, wie KI die medizinische Landschaft verändert.
Zusätzlich spielt KI eine entscheidende Rolle im Verkehrssektor. Autonome Fahrzeuge nutzen KI, um eine sichere Navigation zu gewährleisten, indem sie die Umgebung in Echtzeit analysieren. Diese Fahrzeuge können Verkehrssituationen vorhersagen, auf unerwartete Hindernisse reagieren und somit die Sicherheit im Straßenverkehr erhöhen. Neben autonomem Fahren leisten auch intelligente Verkehrssysteme, die KI-gestützte Datenanalysen nutzen, einen Beitrag zur Optimierung des Verkehrsflusses und zur Verringerung von Staus.
Insgesamt ist die Anwendung von Künstlicher Intelligenz in unserem Alltag breit gefächert und bringt sowohl Effizienz als auch Verbesserungen in zahlreichen Branchen. Die ständige Weiterentwicklung dieser Technologien verspricht, unser Leben auch in Zukunft weiterhin erheblich zu beeinflussen.
Die Herausforderungen und ethischen Aspekte der Künstlichen Intelligenz
Die Entwicklung von Künstlicher Intelligenz (KI) bringt zahlreiche Herausforderungen mit sich, die sowohl technischer als auch ethischer Natur sind. Angesichts der schnell voranschreitenden Technologien stehen Gesellschaft und Wissenschaftler vor der Aufgabe, die Risiken zu minimieren, die mit dem Einsatz von KI-Systemen verbunden sind. Die Frage der Verantwortung ist hier besonders relevant, insbesondere wenn KI Entscheidungen trifft, die erhebliche Auswirkungen auf das Leben der Menschen haben können.
Eine zentrale ethische Überlegung ist die Frage der Bias in Algorithmus-gestützten Entscheidungen. Künstliche Intelligenz lernt aus großen Datensätzen, die vorhandene Vorurteile und Ungleichheiten widerspiegeln können. Wenn diese Daten nicht sorgfältig ausgewählt oder modifiziert werden, kann dies zu diskriminierenden Ergebnissen führen. Der Mangel an Transparenz in den Entscheidungsprozessen von KI-Systemen macht es zudem schwierig, diese Vorurteile zu identifizieren und zu beheben.
Ein weiteres bedeutendes Problem ist der Verlust von Arbeitsplätzen. Viele Unternehmen setzen KI-Technologien ein, um Prozesse zu automatisieren und Kosten zu reduzieren. Während dieses Potenzial für Effizienzsteigerungen und Innovationen bietet, besteht die Gefahr, dass viele Arbeitnehmer durch Maschinen ersetzt werden. Die gesellschaftliche Verantwortung, diese arbeitsbedingten Veränderungen zu bewältigen, bleibt eine dringende Herausforderung.
Auch die Sicherheitsrisiken dürfen nicht ignoriert werden. Die Betrügerei durch KI-generierte Inhalte oder der Missbrauch von Künstlicher Intelligenz für Cyber-Angriffe werfen ernsthafte Fragen zur Sicherheit auf. Es ist wichtig, sowohl rechtliche Rahmenbedingungen als auch technische Schutzmaßnahmen zu entwickeln, um solchen Bedrohungen entgegenzuwirken.
Die Zukunft der Künstlichen Intelligenz: Trends und Entwicklungen
In den letzten Jahren hat die Künstliche Intelligenz (KI) im Schlüsseltechnologien bedeutende Fortschritte gemacht. Es ist jedoch wichtig, die Trends und Entwicklungen zu betrachten, die die Zukunft der KI gestalten werden. Ein herausragender Trend ist die kontinuierliche Verbesserung der maschinellen Lernverfahren. Diese Technologien ermöglichen es Computersystemen, aus Daten zu lernen und Muster zu erkennen, wodurch ihre Entscheidungsfindung zunehmend prädiktiv und präzise wird.
Ein weiterer bemerkenswerter Trend ist der steigende Einfluss von KI auf verschiedene Bereiche, von der Gesundheitsvorsorge über die Automobilindustrie bis hin zu Dienstleistungen und Unterhaltung. Zum Beispiel nutzen Unternehmen vermehrt KI-gestützte Analysen, um personalisierte Kundenerfahrungen zu schaffen und betriebliche Effizienzen zu steigern. In der Medizin kommt KI zunehmend zum Einsatz bei der Diagnostik und in der Entwicklung von Behandlungsmethoden, welche die Lebensqualität der Patienten verbessern können.
Darüber hinaus ist zu erwarten, dass die Integration von KI in alltägliche Technologien weiter voranschreitet. Diese Entwicklung wird nicht nur durch Verbesserung der Hardware und Software ermöglicht, sondern auch durch ein wachsendes Bewusstsein für ethische Überlegungen und den sozialen Einfluss von KI. Verstärkt wird an Prinzipien zur verantwortungsvollen Nutzung gearbeitet, um sicherzustellen, dass KI-Systeme Fairness und Transparenz fördern.
Die zukünftige Entwicklung der KI wird somit nicht nur durch technologische Innovationen geprägt sein, sondern auch durch einen kritischen Diskurs über ihre Anwendung in der Gesellschaft. Prognosen deuten darauf hin, dass KI in den nächsten Jahren weiter an Bedeutung gewinnen wird, was einen tiefgreifenden Einfluss auf alle Aspekte unseres Lebens haben könnte. Der weitere Fortschritt dieser Technologie erfordert jedoch einen verantwortungsvollen und informierten Umgang, um die besten Ergebnisse für die Menschheit zu gewährleisten.