Einführung in große Sprachmodelle
Große Sprachmodelle (LLMs) haben sich als eine revolutionäre Technologie in der modernen Sprachverarbeitung erwiesen. Diese Modelle, die auf tiefen neuronalen Netzwerken basieren, sind in der Lage, große Mengen an Textdaten zu analysieren und zu verarbeiten, um menschenähnliche Konversationen zu erzeugen. Die Entwicklung von LLMs begann mit der Suche nach effektiveren Methoden zur Verarbeitung natürlicher Sprache, was zur Schaffung leistungsstarker Algorithmen und Architekturen führte, die in der Lage sind, komplexe Sprachmuster zu verstehen und zu reproduzieren.
Ein herausragendes Beispiel sind die Transformer-Modelle, die den Grundstein für die gegenwärtige Entwicklung von LLMs legten. Diese Modelle nutzen Mechanismen wie Selbstaufmerksamkeit und Mehrschichtstruktur, um den Kontext und die Beziehungen zwischen Wörtern in Texten präzise zu erkennen. Diese Technik ermöglicht es LLMs, in Echtzeit sinnvolle Antworten zu generieren, was sie besonders wertvoll für Anwendungen wie Chatbots und automatisierte Textgenerierung macht.
Die Bedeutung von LLMs in der heutigen Technologie kann nicht unterschätzt werden. Diese Sprachmodelle haben nicht nur die Art und Weise, wie Maschinen die menschliche Sprache verstehen, revolutioniert, sondern auch zahlreiche Anwendungen in verschiedenen Branchen gefördert. Ihre Fähigkeit, menschenähnliche Konversationen zu führen, verbessert die Benutzererfahrung in der Kundenbetreuung, im E-Commerce und in vielen anderen Bereichen. LLMs tragen somit zur Effizienzsteigerung und Kostensenkung in Unternehmen bei, indem sie wiederkehrende Aufgaben automatisieren und den Bedarf an menschlichem Eingreifen minimieren.
Zusammenfassend lässt sich sagen, dass große Sprachmodelle eine Schlüsseltechnologie darstellen, die die Zukunft der Mensch-Maschine-Interaktion prägt. Durch die kontinuierliche Weiterentwicklung und Verfeinerung dieser Modelle können wir in der Zukunft noch leistungsfähigere und anpassungsfähigere Anwendungen erwarten, die das Potenzial haben, viele Aspekte unseres Lebens zu transformieren.
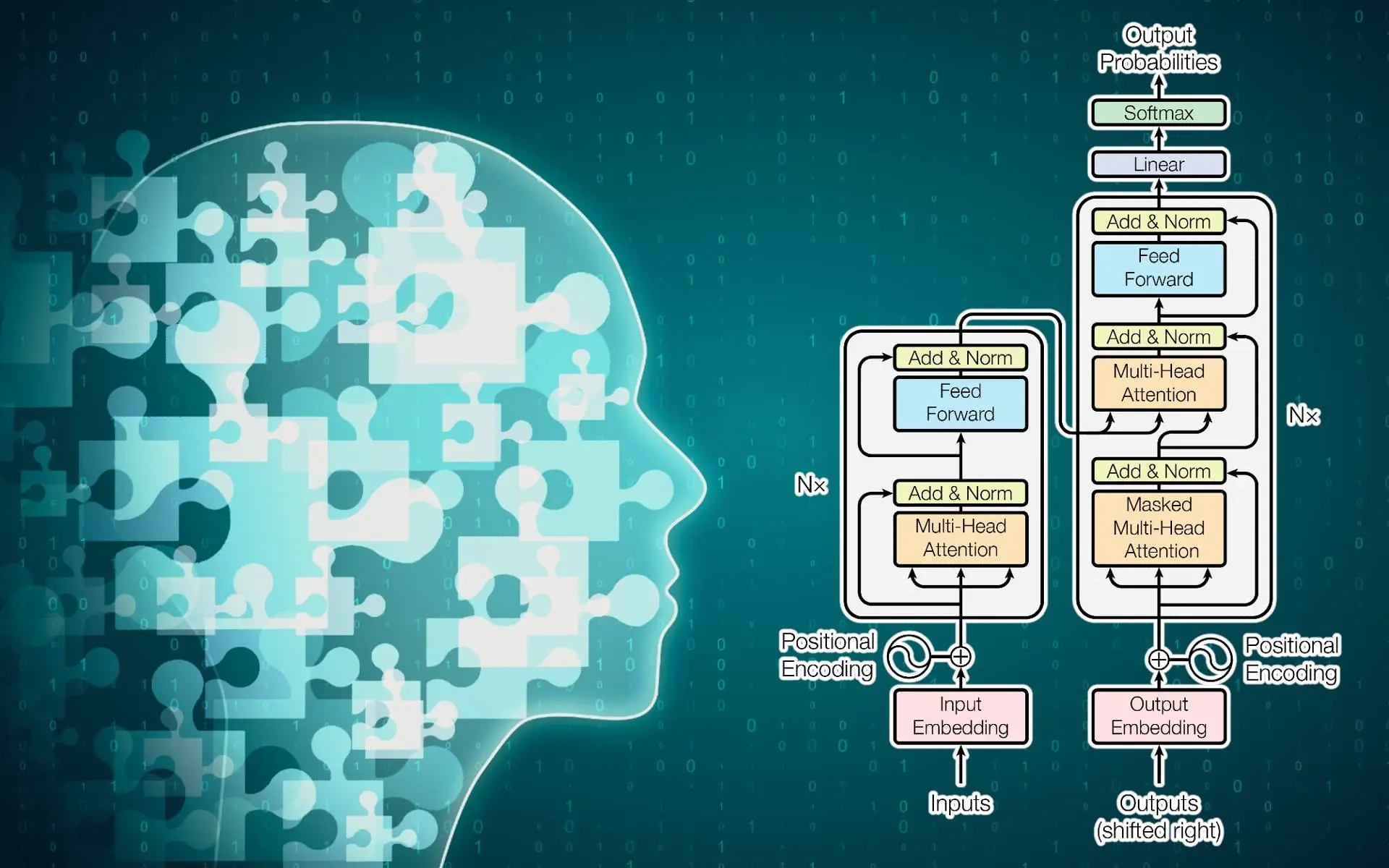
Die Transformer-Architektur: Grundlagen und Funktionsweise
Die Transformer-Architektur ist eine revolutionäre Technik, die die Entwicklung großer Sprachmodelle (LLMs) wie ChatGPT maßgeblich geprägt hat. Im Gegensatz zu vorhergehenden Modellen, die auf rekursiven neuronalen Netzwerken (RNNs) basieren, implementiert das Transformer-Modell eine völlig neue Struktur, die sich stark auf den Mechanismus der Aufmerksamkeit stützt. Diese Struktur ermöglicht es, Informationen effizienter zu verarbeiten und große Textmengen schnell zu analysieren.
Die Grundkomponenten eines Transformers bestehen aus Encoder- und Decoder-Elementen. Der Encoder hat die Aufgabe, die Eingabedaten in eine interne Repräsentation zu verwandeln, während der Decoder diese interne Repräsentation nutzt, um die Ausgabe zu generieren. Diese Komposition ermöglicht es dem Modell, Informationen kontextuell zu verarbeiten und relevante Zusammenhänge innerhalb der Daten zu erkennen.
Ein wesentlicher Bestandteil der Transformer-Architektur ist der Selbstaufmerksamkeitsmechanismus, der es dem Modell gestattet, Beziehungen zwischen Wörtern in einem Satz zu erlernen, unabhängig von deren relativer Position. Durch die Berechnung der Aufmerksamkeit können Modelle gewichten, welche Wörter im Kontext wichtiger sind. Dies ist eine entscheidende Verbesserung gegenüber früheren Ansätzen, die oft Schwierigkeiten hatten, Langzeitabhängigkeiten zwischen Wörtern zu berücksichtigen.
Ein weiterer Vorteil der Transformer-Architektur ist die Möglichkeit der Parallelverarbeitung. Im Gegensatz zu RNNs, die sequenzielle Datenverarbeitung erfordern, können Transformers die gesamte Sequenz gleichzeitig bearbeiten. Dies führt zu einer erheblichen Steigerung der Berechnungseffizienz und verkürzt die Trainingszeiten. Insgesamt bildet die Transformer-Architektur das Rückgrat vieler modernster Sprachmodelle und hat die Landschaft der natürlichen Sprachverarbeitung geprägt.
Der Attention-Mechanismus: Verstehen von Wortbeziehungen
Der Attention-Mechanismus ist eine fundamentale Komponente in der Transformer-Architektur, die es großen Sprachmodellen ermöglicht, komplexe Bedeutungen und Beziehungen zwischen Wörtern zu erfassen. Ein zentraler Aspekt dieses Mechanismus ist das Konzept der Self-Attention, das es dem Modell erlaubt, den Einfluss eines jeden Wortes auf die anderen Wörter im Satz zu bewerten und zu gewichten. Im Gegensatz zu früheren Modellen, die auf sequenzieller Verarbeitung basierten, analysiert der Attention-Mechanismus alle Wörter gleichzeitig, wodurch er die Erfassung von Kontext und Bedeutungsnuancen erheblich verbessert.
Der Self-Attention-Mechanismus funktioniert, indem er für jedes Wort im Eingabetext eine Beziehung zu allen anderen Wörtern herstellt. Dies geschieht durch die Berechnung von drei verschiedenen Vektoren: dem Query, dem Key und dem Value. Ein Wort wird in einen Query-Vektor umgewandelt, während alle anderen Wörter in Key- und Value-Vektoren umgewandelt werden. Der Output eines Attention-Mechanismus wird dann durch die Berechnung des Skalarprodukts zwischen Query- und Key-Vektoren erlangt. Dies bestimmt, wie relevant ein Wort für ein anderes ist, und wird häufig durch eine Softmax-Funktion normalisiert, um die Gewichte zu erhalten. Diese Gewichte geben an, inwiefern ein bestimmtes Wort zu einem anderen führt.
Durch dieses Verfahren kann das Modell zahlreiche Beziehungen und Abhängigkeiten im Text erfassen, wodurch es die Leistung beim Verstehen und Generieren von Sprache erheblich steigert. Der Attention-Mechanismus ermöglicht es großen Sprachmodellen, den Kontext dynamisch und flexibel zu berücksichtigen, was zu einer signifikanten Verbesserung in Aufgaben wie maschinellem Übersetzen, Textzusammenfassung und sentimentanalytische Bewertungen führt. Dieser Mechanismus ist somit nicht nur eine technische Errungenschaft, sondern auch der Schlüssel zur Leistungsfähigkeit moderner Sprachverarbeitungssysteme.
Die Anwendung von LLMs in der Praxis: Beispiele und Herausforderungen
Große Sprachmodelle (LLMs) haben in den letzten Jahren enorme Fortschritte gemacht und finden Anwendung in verschiedenen praktischen Szenarien. Ein herausragendes Beispiel ist die Implementierung von LLMs in Chatbots, die in Kundenservice-Anwendungen eingesetzt werden, um automatisierte Antworten auf häufig gestellte Fragen zu liefern. Diese Chatbots können die Interaktion mit Kunden verbessern, indem sie schnelle und präzise Informationen bieten. Darüber hinaus sind LLMs auch effektiv in der automatisierten Übersetzung, wo sie den Sprachbarrieren zwischen Menschen begegnen, indem sie Texte in verschiedene Sprachen übersetzen und dabei den Kontext und die Nuancen der ursprünglichen Botschaft berücksichtigen.
Ein weiterer interessanter Anwendungsbereich ist das kreative Schreiben, wo LLMs als Unterstützung für Autor*innen dienen können. Sie helfen dabei, Ideen zu generieren oder Textentwürfe zu überarbeiten. Dies eröffnet neue Möglichkeiten für die Zusammenarbeit zwischen Mensch und Maschine im kreativen Prozess.
Trotz dieser vielversprechenden Anwendungen sehen sich Entwickler und Anwender auch Herausforderungen gegenüber. Ethische Überlegungen spielen eine wesentliche Rolle, da vorgefasste Meinungen in den Trainingsdaten ungewollt zu diskriminierendem oder voreingenommener Sprache führen können. Solche Vorurteile können das Nutzererlebnis beeinträchtigen und zu schädlichen gesellschaftlichen Auswirkungen führen. Darüber hinaus müssen Sicherheitsbedenken angesprochen werden, insbesondere in sensiblen Bereichen wie Gesundheitsversorgung oder rechtlicher Beratung, wo fehlerhafte Informationen erhebliche Konsequenzen haben können. Die Risiken einer fehlerhaften Nutzung, wie die Möglichkeit von Manipulation und Missbrauch von LLMs, erfordern daher eine umfassende Diskussion und sorgfältige Regulierung.
